
- Co dalej
- Co się stało wcześniej
- Uzasadnienie dla 8k
- Wideo wektorowe
- Czy wszystko jest takie proste?
- Wyrafinowane dynamiczne sceny
- O ile to możliwe
Pomóż w opracowaniu witryny, udostępniając artykuł znajomym!
Postęp techniczny jest interesującą rzeczą. Ci, którzy urodzili się w ciągu ostatnich sześćdziesięciu lat, widzieli tak wiele zmian, jak wielu nie widziało poprzednich pokoleń. Wśród zmian, do których jesteśmy przyzwyczajeni, wzrost rozdzielczości wideo ma znaczną wagę.
Z naszej strony wszystko dzieje się szybko. Każdy, kto ma dziś do czynienia z profesjonalnym filmem, przywołuje tylko zwykłe wideo w rozdzielczości. Wielu z nas używa go do dziś, ale ważnym paradygmatem roboczym jest hd.
Co dalej
Dalej na horyzoncie 4k. I z niemal nieprzyzwoitym pośpiechem mówimy o 8k. W rzeczywistości wiele firm, na przykład Sony i BBC, wykorzystujących wiele formatów wideo o rozdzielczościach znacznie większych niż hd, używa takich definicji, jak „tylko bez zezwolenia” (mimo że po Sony oznacza to, że rozdzielczość to nie wszystko, istnieją też inne, dość ważne czynniki, na przykład poprawa jakości gamy kolorów i kontrastu.
Każdy chce zobaczyć najlepszy obraz. I nie ma absolutnie nic złego w stwierdzeniu, że - w innych równych warunkach - jeśli możliwe jest nagrywanie obrazu w formacie wysokiej rozdzielczości, to jest dokładnie to, co należy zrobić.
Idea cyfrowego wideo w tej chwili tak dobrze się wzmocniła i głęboko zasiadła w umysłach ludzi. Co najmniej słowo „piksel” jest w języku każdego, tak jakby zawsze było elementem języka.
W rzeczywistości nie tak dawno temu nie był doskonały. Ani lampy elektronopromieniowe, ani nagrywarki VHS, jak również inne typy analogowych urządzeń wideo nie działały z pikselami.
Co się stało wcześniej
Przed erą pikseli wideo rejestrowano jako stale zmieniające się napięcie. Nie był skwantyzowany, no może, w odniesieniu do końca linii skanowania lub do zakończenia pola ramki.
Cyfrowe wideo jest takie samo. Jest wyświetlany w liczbach. Wygląda bardziej jak „rysowanie według liczb”, z tą różnicą, że zamiast reprezentować obraz według rodzaju linii oddzielających różne kolory, na obraz nakłada się jednolita siatka. Praktycznie każdy element w tej strukturze komórkowej jest pikselem, w którym osadzona jest liczba odpowiadająca kolorowi danej komórki. Wszystko jest niezwykle proste i szybkie!
Ale prawdopodobnie nie jest to jedyny sposób prezentacji obrazów. W naturze absolutnie nie ma siatki, która bezwarunkowo reaguje na nałożoną siatkę pikseli.
Kiedy się nad tym zastanowimy, faktycznie trzeba dołączyć wyobraźnię, aby zrozumieć, jak coś subtelnego i istniejącego w rzeczywistości, na przykład motyla, można przedstawić za pomocą ciągu kodu binarnego. Te dwa pojęcia na pierwszy rzut oka odnoszą się do różnych wymiarów. W rzeczywistości ucieleśniają rzeczywistość analogową i cyfrową.
Ale cud cyfrowego wideo polega na tym, że w obecności wymaganej liczby pikseli ich nie zauważymy. Nasz mózg widzi dyskretny obraz, jakby był analogowy, dopóki nie osiągniemy bardzo blisko.
To jest pomysł. Jeśli nie masz wystarczającej liczby pikseli i siedzisz bardzo blisko, możesz zobaczyć siatkę.
Prawie wszyscy ludzie czytający ten materiał już o tym wiedzą i wracamy do tej części teorii tylko po to, aby pokazać, że w rezultacie piksele nie są najlepszym sposobem na prezentowanie obrazów. Tak, jeśli oglądasz HD w telewizorze „normalnym”, obraz wygląda świetnie. Ale jeśli chcesz mieć podwojoną przekątną TV (odpowiednio 4 razy większy obszar), po prostu przejdź do 4k.
Uzasadnienie dla 8k
Dla 8k istnieją prawdziwe powody, by chcieć tego formatu. Na przykład, gdy niektóre piksele są nieodróżnialne zarówno w hd, jak i 4k, to po dokładnym rozważeniu nachylonych linii, można zobaczyć nierówne krawędzie, takie jak zęby piły, a im bliżej linii do linii poziomej lub pionowej, sytuacja pogorszy się dalej. Można nawet powiedzieć, że zniekształcenia zwiększają pikselację, czyniąc ją nieco bardziej charakterystyczną. Czterokrotna liczba pikseli poważnie ogranicza zniekształcenia.
Wiele momentów prowadzi do pewności, że istnieją inne ulepszenia, które przyniosą więcej korzyści niż przejście do 8k, ale prawdopodobnie powinieneś uciec od pojęcia pikseli.
Zwróć uwagę na fakt, że będziemy stale zajmować się pikselami w przypadku mówienia o renderowaniu obrazu na ekranie telewizora. Dopóki nie zostanie wynaleziona inna metoda, podobna do naturalnego wyświetlania wideo, która wiąże się z odrzuceniem metody dzielenia obrazu na najprostsze komórki, będziemy stale patrzeć na świat poprzez przestrzennie skwantyzowaną siatkę zarejestrowanych lub przesyłanych obrazów. Ale to, co można radykalnie zmienić, to sposób przechowywania wideo.
Wideo wektorowe
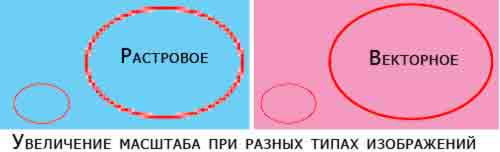
Najwyraźniej przesuniemy się w kierunku wideo wektorowego. Jeśli jesteś grafikiem lub zajmowałeś się Corel Draw, a także Adobe Illustratorem przez ostatnie 30 lat, to znasz różnicę między grafiką wektorową i rastrową. Obraz rastrowy jest znaną siatką pikseli zawierającą liczby równe kolorowi komórki elementarnej.
Wektor to inny temat. Zamiast wyraźnego określania koloru każdej pojedynczej części obiektu, wektor jest meta opisem obiektu. Chociaż jest to już bardzo szczegółowe metadane. Jednak jakość obrazu nie zmienia się podczas skalowania obrazu wektorowego:
Weźmy na przykład łacińską literę „I”. W kroju pisma bezszeryfowego takiego jak ten łatwo jest opisać go tak samo, jak piszesz. Standardowo jest to coś w rodzaju „czarnego prostokąta zorientowanego pionowo, gdzieś około 5 mm wysokości i 0, 5 szerokości”. Jeśli zastosujesz się do tego opisu, otrzymamy idealne „ja”. Nie musisz martwić się o piksele: w tym opisie jest wystarczająco dużo danych. Kształt i kształt obiektu pochodzą z opisu i tyle.
Czy wszystko jest takie proste?
Nie zapominaj, że „i” w dolnej części jest trudniejsze do opisania niż w górnej. Problem tkwi w bardziej złożonym opisie ostatniego prostokąta, który jest znacznie krótszy, i bardziej złożonym opisie kropki nad nim w postaci czarnego koła.
Jeśli weźmiemy takie litery jak „K” lub „D”, zadanie to stanie się bardziej skomplikowane w opisie tych liter. Nie oznacza to jednak, że zadanie jest niemożliwe i nie ma na to rozwiązania. W końcu wszystkie czcionki i zestawy słuchawkowe zostały już wcześniej opisane.
Najważniejszą zaletą tej metody jest to, że dzięki poprawnemu opisowi obiektu można go odtwarzać zarówno na małej, jak i na dużą skalę, bez utraty jakości obrazu. Zadanie polega tylko na tym, że podczas wyświetlania będzie musiało zostać przekształcone (zrasteryzowane) ponownie w „formę pikselową”. Nastąpi to za pomocą oprogramowania wbudowanego w monitor lub telewizor. Tylko podstawa zajmie obiekt opisany wektorem, a system skonwertuje go w zależności od rozdzielczości ekranu. A ponieważ obraz nie będzie rastrem, kształt okręgu nie będzie opisany przez rozdzielczość pikseli, a bieganie zwierząt i sportowców nie będzie składało się z siatki pikseli.
W rezultacie film nie będzie cytowany przez taki parametr jak rozdzielczość, ale będzie to tylko opisany film. Należy zauważyć, że kodowanie wektorowe będzie ograniczone do minimum.
Wyrafinowane dynamiczne sceny
Przedmioty w filmie i teraz nie zajmują szczególnie dużej kwoty. Ale co ze złożonymi scenami z filmów i innych filmów? Istnieje pomysł na zrobienie tego na podstawie procesu zwanego „autotrace”. Jeśli umieścisz kalkę na obrazie, możesz dokładnie skopiować główne linie obrazu. Następnie należy usunąć i pokolorować lub zastosować gradient według własnego uznania. Film ma również istotę lub opis. Kombinację krzywych można opisać za pomocą techniki Beziera. Istnieje założenie, że w naturze nie ma takich linii, których nie można opisać.
Warto przypomnieć, że jest to tylko teoria, która może napotkać nieoczekiwane problemy. Jednym z tych problemów są bardzo złożone sceny, które chcesz wyświetlić na dużym ekranie.
Główną ideą tego filmu jest dokładność opisanego obrazu. Następnie następuje jego konwersja w powiększonym formacie. Przewiduje się, że jakość nie zostanie utracona przy żadnej rozdzielczości.
Proces ten można osiągnąć, opisując obraz bezpośrednio podczas samego fotografowania lub jako oddzielną operację konwersji.
Jeśli chodzi o liczbę klatek na sekundę, podobnie jak dzisiejsze kodeki H.264 i MPEG, zmiana obiektu będzie śledzona tylko wtedy, gdy się porusza. Jedyną różnicą w zasadzie wideo wektorowego od kodeków będzie to, że ruchy zostaną opisane dokładniej.
Według twórców szybkość klatek może być podobna do dzisiejszej zmiennej przepływności. W przypadku scen statycznych może być mniej i przy dynamicznych scenach - więcej.
O ile to możliwe
Sądząc po opisie - wszystko jest możliwe. Zasób YouTube jest już gotowy do pochwalenia się filmem opublikowanym na temat wyników British University of Bath. Tam trwają prace nad stworzeniem nowego kodeka opartego na wektorze.
Ponadto programiści nie zapominają o takim formacie jak 3D. Równolegle trwają prace nad trójwymiarowym opisem wektorowym z dodatkowymi teksturami. Zasada jest taka sama, z wyjątkiem tego, że telewizor będzie również wyposażony w dodatkowy sterownik, który rozpozna te opisy wektorowe.
Niewykluczone, że nikt nie próbowałby niczego wymyślić, gdyby nie jeden, a raczej niewiarygodny problem 8 tys. Związany z ogromną ilością informacji. Najprawdopodobniej jest to jedyny powód, dla którego trwają poszukiwania w celu znalezienia bardziej wydajnych metod kodowania, które nie zwiększą już znacznego zasobu.